Breaking Down Networking - From the first message on the Internet to Daemons listening on different ports.
What happens when you type google.com in your browser and press Enter


"LO", that was first message sent on the internet. Though "Login" was the message that was intended message but, the system crashes.
“Hence, the first message on the Internet was 'LO' — as in 'Lo and behold!',” Kleinrock said. “We didn't plan it, but we couldn't have come up with a better message: succinct, powerful and prophetic.”
Kleinrock was the team lead of the project and the first message on the surface of the earth. The message was sent from UCLA to Stanford. One thing I find interesting about the history of the internet is that, without the US military trying to improve communication, there might be nothing called the internet. In fact, ARPANET, which is the precursor to the modern internet, was sponsored by the US Department of Defense. Accolades should also be given to all the professors who worked to see the creation of the internet. Without their hard work, the internet and most of the other technologies would not be possible.
Networking is one of the most interesting fields to me, and it is fun when learning. Someone gets to understand what the internet, which seems like magic, is. In this blog, I will try my best to explain some important concepts in the field of networking, and I hope it will be as fun for you as it is for me. Since the internet and the networking field are so vast, with many researches and textbooks written on them, it would be nearly impossible to summarize everything in a single blog. My approach will be to pick a fascinating topic and then summarize networking through it. The topic which I will be using is what happens when you type https://www.google.com in your browser and press Enter. There is some probability that, along the way, I might talk about databases; nevertheless, let's go. It's also important to note that this topic is just on the World Wide Web (developed by Tim Berners-Lee), which is one of the important parts of the internet.
A network is the combination of two or more computers sharing information. The internet is just the whole combination of computers sharing information between themselves. The internet is the combination of many networks. We have different types of networks: WAN, LAN, PAN, WLAN, CAN, etc. Where "AN" stands for "Area Network," "L" stands for "Local," "P" stands for "Personal," "WL" stands for "Wireless Local," and "C" stands for "Campus." The biggest one is the Wide Area Network to which we all connect whenever we join using a service provider. The WAN is referred to as the internet. A personal network might just be you connecting your headset using Bluetooth to your laptop. A local network, as its name suggests, is just the network within a local area, while Campus is within the campus. Simple and straightforward.
There are lots of ways you can connect to the internet or a network. You can connect to the internet through Ethernet cable, Wi-Fi, fibers, Bluetooth, cellular network, etc. The network equipment that provides those ways are often called network media. I will leave the theoretical and move to the main point of this blog. Let's go.
Before moving ahead, I need to explain this very important concept, which we will be using very often.
Important Networking Concept
Server and Client: Literally, all computers can be used as a server; a server is just any computer that serves or provides information/resources to a client, which is another computer requesting the information. Any website or app that you visit on the internet is basically a bunch of files stored somewhere and served to you (the client) whenever you request them. You can basically turn your computer into a server. However, your computer has some limitations and might not be a good server. One of the main requirements for a server is that it must be up all the time to serve the client. This is the reason why we have specialized computers that are basically made to serve resources. They mostly do not have a monitor like some other parts of personal computers and most of the apps we use, but essentially they have everything a computer has with more optimization for them to function as a server. They are much bigger and are kept in a data center. We say a client makes a request and the server gives a response.
Virtualization and Container: This is basically a technology that makes it possible to have multiple computers on a single computer with their own resources like RAM, CPU, etc. Virtual machines are basically software that serves as a computer. For example, if you run a virtual machine on your computer, the virtual computer will have its own CPU, RAM, etc., and they will be sourced from the computer you are running it on. Containers have a similar concept of sharing computer resources between instances of containers (basically a computer). Both differ in the way they work. While containers are more commonly used nowadays, the most common container technology is Docker. With these two technologies, companies like Amazon and Microsoft can create bigger servers and split them into multiple servers to sell to people who need them.
IP Address: I defined the internet as multiple networks communicating and sharing resources with each other. I also defined a network as a combination of computers and devices communicating and sharing resources with each other. So, the internet is networks of networks. The question now is, if a computer wants to send resources to another computer or even communicate with another computer, how will they identify each other in this very big network? The answer is very simple: they use IP addresses. An IP address is a unique number given to a computer in a network for identification purposes. We have two types of IP addresses: IPv4, which is 32 bits long and separated into 4 parts by dots. Each part is 8 bits long. We also have IPv6, which is 128 bits long and is separated into 8 parts separated by colons. Each part is 16 bits long. IPv6 was created because IPv4 is not enough to serve every device on the internet as the internet grows. We can basically have over 4 billion IPv4 addresses, which means only over 4 billion devices will be able to join the internet. But IPv6 has about 340 undecillion numbers, which is about 38 zeros.
These IP addresses are actually numbers:
IPv4 example: 127.0.0.1
IPv6 example: 2001:0db8:0000:0000:0000:8a2e:0370:7334 or 2001:db8::8a2e:370:7334 in shortened form.
One thing to note is that there are many types of servers. In terms of their structure, we can have hardware-based servers or software-based servers. Hardware-based servers run directly on a computer, while software-based servers are the ones obtained from virtualization or containers. We can also divide servers based on their functions. We have web servers that basically serve you, the client, a website; mail servers, which serve you mail; database servers, which store, serve, and manage information and data; file servers, which serve files; DNS servers, which we will talk about later. There are many more different kinds of servers based on what they serve.
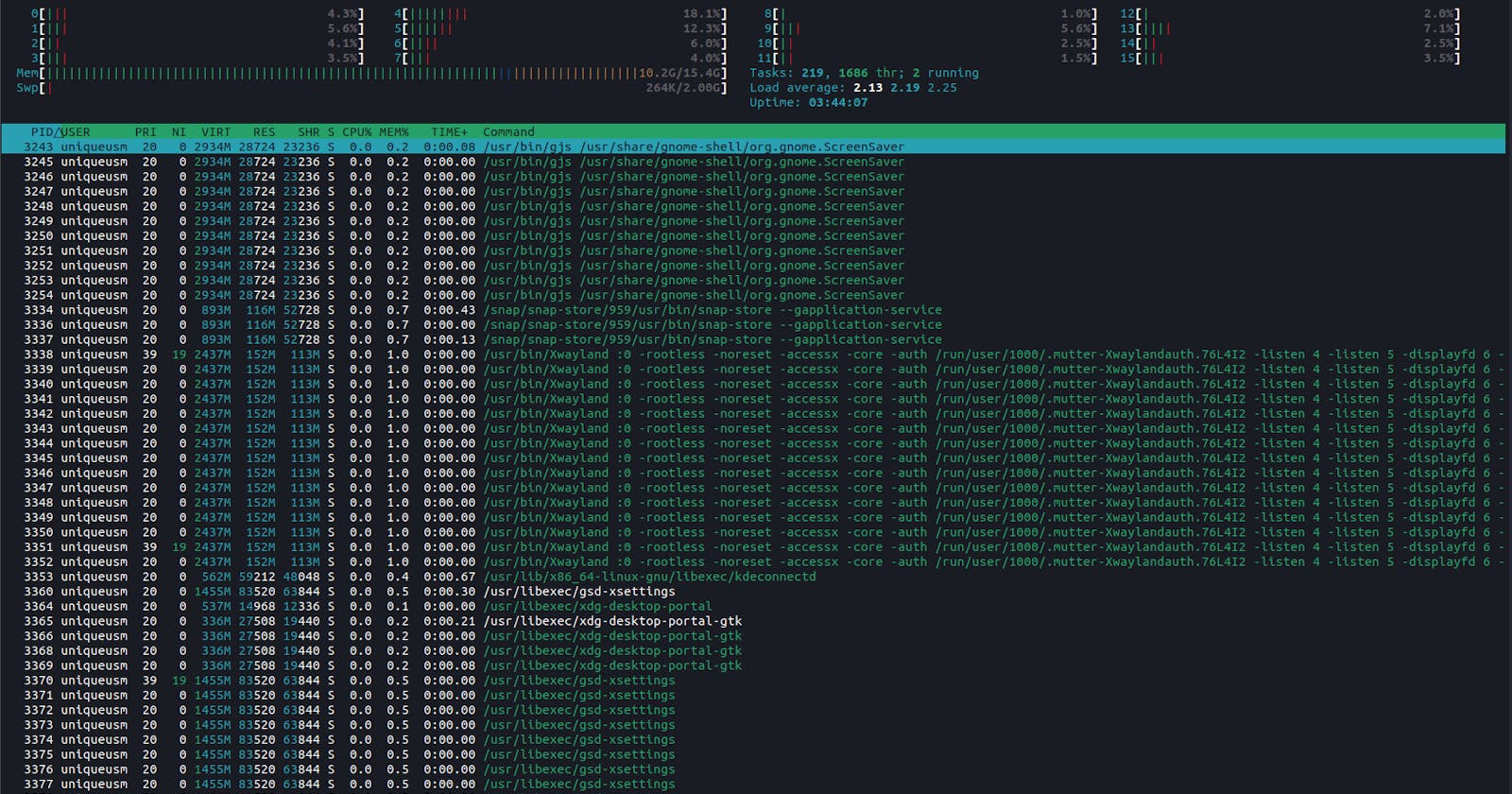
Port Number: I was going to put port numbers together with the IP address, but there is something important that I want you to take note of, which is why I separated the two. Let's go. Actually, whenever there is communication between two computers, it is actually two processes or services running (a process is an instance of a program running on a computer. If you use Linux, you should know better). Everything running on your computer is actually a process. You open a browser, you open an app; they are all processes. So, when two computers are communicating, there is a process in each computer to manage the process. You can use commands like htop, top, ps to manage processes on your computer.

The above is the output of the htop command on my Linux terminal. You can learn more about processes and how to manage them. Let's move on; there is something called daemon processes. They are very important processes that automatically open and run in the background when you turn on your computer. So, in respect to the networking field, for each service like SSH, web server, app server, etc., a daemon process is always running in the background to manage them. There is common terminology used in networking and the web; they always say that the web server is listening on port 80 for HTTP requests. But, what is actually happening is that it is actually a daemon process that is listening on that port for requests from other computers. Port numbers are just a way to distinguish between services that a computer can provide to another or to distinguish different ways in which a computer communicates with another. It is also a way to identify which processes to go to for the data. So, when you send an email to someone, there is a dedicated port number that the email will go to. If it is a web request, there is a dedicated port that the request will go to; if it is SSH, there is a dedicated port it will go to.
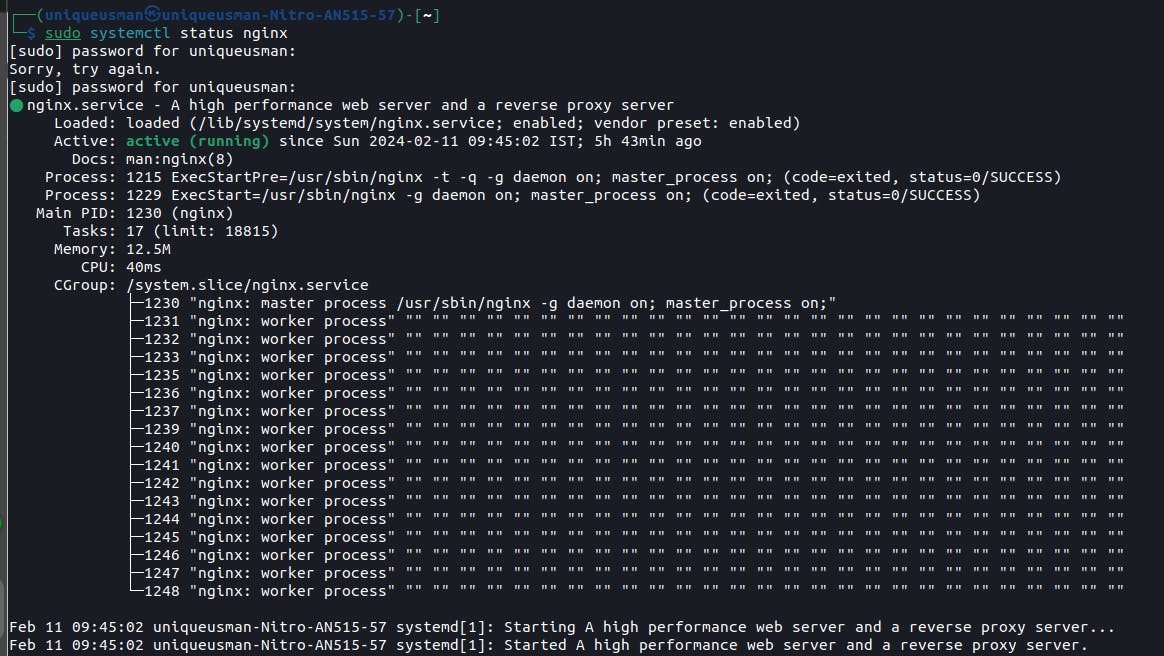
The above is a picture of a web server deamon process that is listening for http request, if the status is not active, any request coming to the web server will not be accepted.
What happens when you type google.com in your browser and press Enter
Whenever you open your browser (e.g., Chrome, Firefox, Edge, etc.) and type the first letter, through some algorithm which is based on your search history and popular stuff around you, the browser will try to autocomplete it for you.
Let's say you type www.google.com in your browser and click Enter. Many things will happen immediately. One of the first things that happens is your keyboard sending some interrupt signal to the CPU of your computer and all sorts, but because we are not here to discuss computer architecture, we will leave that alone. We will focus on the networking and some portion of the database of the whole process.
These are the steps which happen:
Domain name resolution through DNS: One important thing to note is that all websites are basically stored on a server living somewhere, waiting for requests from a client for the website they are hosting.
So, basically, when you type a web address into a browser, you are looking for a server or computer on the internet. But, as we all know, computers are only identifiable through numbers, yet you type letters into the browser. So, the system that helps you change the letters, which is called the Domain Name System (DNS). This is not as simple as you might think; changing the domain name to an IP address involves a lot of steps. Let's talk about it.
The first step the DNS system takes to resolve the domain name to an IP address is to check its cache if it has it.
If the browser does not have it in its cache, it asks the operating system if it has it. In the earlier days of the internet, the domain names and their IP addresses were always kept by the operating system (OS) in a file. For Linux, it can be found in the /etc/hosts file. But as time goes on, many websites started appearing, which means there is a need for another way to resolve domain names to IP addresses.
If both the browser and the OS do not know how to resolve the issue, then the resolver is contacted by the OS. The resolver is usually your ISP - the internet service provider (For example, Airtel is a well-known ISP in Nigeria, India, and other African countries). Actually, the ISP does not have the IP address for the domain; it only knows where to find the Root server. The root server basically knows how to find the root domain, also known as TLD (top-level domain).
TLD and Root server: All the addresses (also known as URLs - Uniform Resource Locators) that you type into your web browser can be defined into multiple parts. Check the picture below to understand.
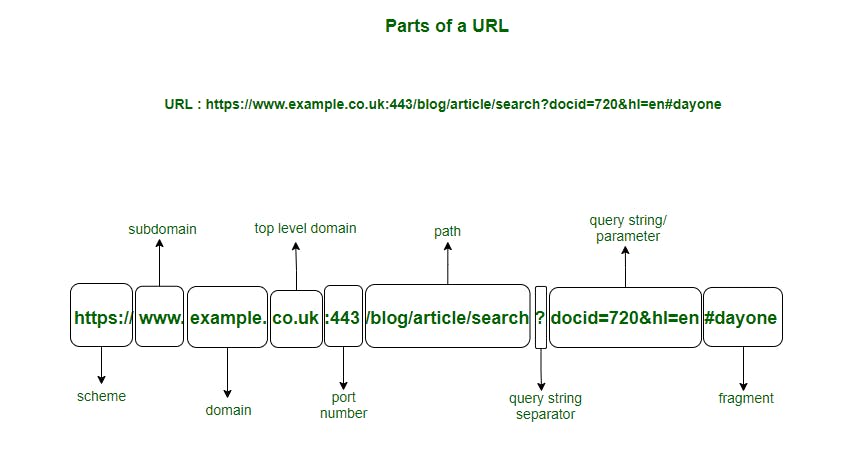
Credit :- GeegforGeeks(https://www.geeksforgeeks.org/components-of-a-url/)
We might talk later about the components of the URL, but for now, you will notice that the TLD here is co.uk. Other well-known TLDs are .com, .org, .net, etc. Basically, the root server has a list of these root domains and their IP addresses, i.e., where you can find them. Also, do not forget, the TLD is also another server, which is why it has its own IP address.
Since our address is google.com and the full address is https://www.google.com, the TLD here is .com. After the root server gives the IP address of the .com server to the resolver, the resolver will connect with the .com server and ask for the IP address of www.google.com. The .com server also does not have the IP of the website but has the authoritative name server for the address we are looking for the website.
Name server: Whenever you register a website, the IP address of where your web server is located will be added to your name server. The name server contains the URLs and their corresponding IP addresses. For each IP address, there can be up to 2-12 name servers for distribution based on location and to prevent a single point of failure. Note that the name server is actually provided by the company that provides the domain name. Additionally, there is something called the Domain Registrar, which communicates with the TLD registry to provide the authoritative name servers for newly created sites.
When the ISP receives the IP address from the name server, the ISP or resolver will provide the address to the OS for caching and to the browser for caching, so that in the next round, there would not be any need for all this round trip. Then the browser can start making requests to the server where the website or the resource it is looking for can be found.
OSI and TCP/IP model:
This is a very interesting and important part as well. There are a lot of computers and devices connecting together on the internet. Most of these devices are created by different people, companies, and even countries. The question is: how do you make a computer made by Apple communicate with another one made by HP? That is where all these different models come in. These models are ways to ensure that when HP creates its own devices, they will be able to communicate with those created by Microsoft. These models basically specify how all these devices should be made to communicate with each other despite coming from different companies or countries. The OSI model is more of a conceptual form and is mostly used for teaching. OSI stands for Open Systems Interconnection, and it specifies the 7 layers that devices should have to participate in networking.
OSI Model
Application Layer - Manage the user interface like apps and browsers. Data at this layer is in the form of messages or data streams.
Presentation Layer - Manage how the information is presented to the user. It includes encryption, translation and compression of data. Data at this layer is represented in a format that is understandable by both the sender and the receiver, regardless of their respective differences.
Session Layer - Manage the sessions betwween network communicating with each other. Data at this layer is organized into sessions or conversations.
Transport Layer - Manage how information is being transported between each other. Data at this layer is organized into segments or datagrams.
Network Layer - Manage how computer create connection with each other in the internet. Data at this layer is in the form of packets.
Data Link layer - Manage how computer create connection with each within a network. Data at this layer is organized into frames
The physical layer - Manage how the data in bit form is being from one device to another. Data at this layer is in the form of raw bits, which are transmitted as electrical or optical signals.
The TCP/IP combined the application, presentation and session layer together into application layer.
Let discuss more about this layer and some important component using TCP/IP model.
Application Layer: It is the one that most times the user interacts with. Software like web browsers, email clients, and apps rely on the application layer to communicate. One very important thing is that software applications are not part of the application layer. The application layer is responsible for the protocol that the software relies on to present meaningful data to the user. I talked about protocol now. Protocol is basically the set of rules that guide how a particular data is sent on the internet. HTTP and HTTPS protocols are the rules that guide how website files are being sent on the internet, SMTP for emails, SSH protocol for secure shell, FTP for file transfers, etc. It also manages the session and the presentation of the data.
Transport Layer: This defines how the data is being transported. The transport layer includes the TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). TCP is slower but reliable as it ensures the client receives all the data. Services which require that the data is received completely use it. Files, websites, and emails use TCP as you want to ensure that the client receives all the data completely. UDP is very fast but not reliable; it just keeps throwing the data at the client. It does not care about whether the client receives the data or not. But it is very fast. Video streaming uses the UDP protocol. The port number falls in the transport layer. Some services like SSH do not require the application layer and are built on top of this layer.

Network Layer: This is where the connection is set up, and the IP address falls into this layer. The Transport layer depends on this Network layer. This is also where routing takes place. A router is simply a device that sends data from one network to another. NAT (Network Address Translation) works at this layer. Mostly, when you connect to the internet on a Wi-Fi or network, the IP address shown to the outside world is actually the Wi-Fi address. So, basically, all the devices sharing an internet connection will have the same public address, i.e., if you connect your phone, laptop, etc., to a single network, they will all share the same public IP address. NAT is the way to change the public IP address which your device uses to connect to the internet to a private address which is used to recognize a particular device in a network.
Data Link Layer: This is the layer that is responsible for ensuring that data gets to the device that owns the data within a network. When the data arrives, it comes to the network, and to ensure that the data reaches the devices which own it, this layer is in charge. It uses ARP (Address Resolution Protocol) to ensure that data is sent to the correct device. ARP basically maps the private IP address to the MAC address. Media Access Control is basically a unique number assigned to a device by the manufacturer, and it mostly does not change.
Physical Layer: This includes the physical equipment involved in the data transfer. Earlier in the days, devices were connected using Ethernet cables and wires to transfer data. There are different ways to connect them; they are called topologies. Some of them are bus, ring, star, etc. Now we have wireless forms of connection like Wi-Fi, Bluetooth, etc. The fastest way for connection is the fiber cable, and it is used for long-distance connections.
Security
At the begining of the internet, security was not that important as the people on the internet are very small in number and probably knows themselves. As the number of internet start growing, terms like hacking and cyber attacks started coming up. This is the point were the needs for security started arising. Security is just what it is, how do we prevent information from getting into the hand of unathorized user, how do we ensure unathorized user do not get access to the systems and computers. Security is implement in almost all the layers of the OSI/TCP models and each with it own speciality and function. Some security is done through encryptions and some through authentication. I will talk about some of them. Let's go.
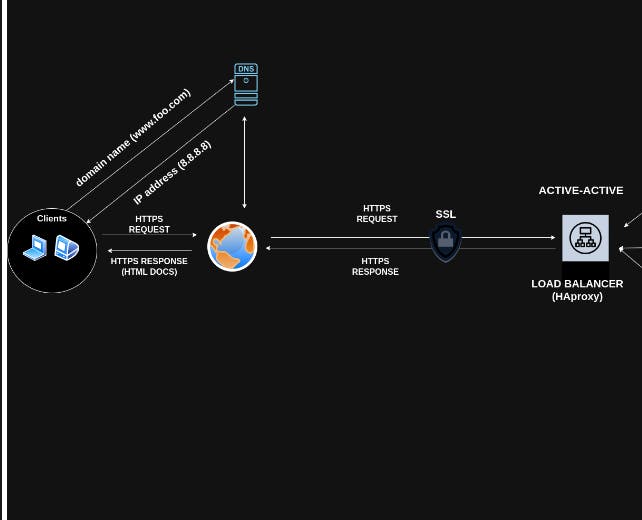
HTTP stands for hypertext transfer protocol and it is the protocol use for transfering web files. It uses port 80. There is another type of HTTP which is known HTTPS. The S stands for secure. Basically, the secure form of HTTP is the HTTPS. It uses SSL (secure socket layer) for it's security. Nowadays SSL is refers to as TLS transport layer protocol. The security is build upon TCP in Transport layer. SSH is also another form of secure way of transfering information on the internet. It also a Transport layer protocol and port 22 for it communication. There are some common attacks one should aware of which is the SQL injection and DoS attacks(Denial of Service). At this point let continue with our discussion on what happens when you type the google.com on your address.
Your browser now have the IP address of the computer/web-server that is going to serve the content requested for. Your browswer will now make HTTP request if the website is not secure else it will make HTTPS request along with some information of the computer. Most browser uses Padlock to show that website is secure. Underneath, HTTPS is actually build on top of TCP request or UDP. There is also something TCP handshake which is just a way computer connect with server and ensure the data transfer is secure. One thing to note is there is different form of HTTP, we have HTTP0, 1.1, 2 etc. Normally, when you request for a website, it is always combination of many files and images and most time the entry point is the index.html file. Before HTTP1.1, browser need to make TCP connection for every request for a file from the same. This really slow down the connection and HTTP1.1 was made which actually just use one TCP connections to request for the data. The concept of using one TCP connections with another is called Keep-Alive. HTTP2 and 3 is similar to 1.1 with little differences.
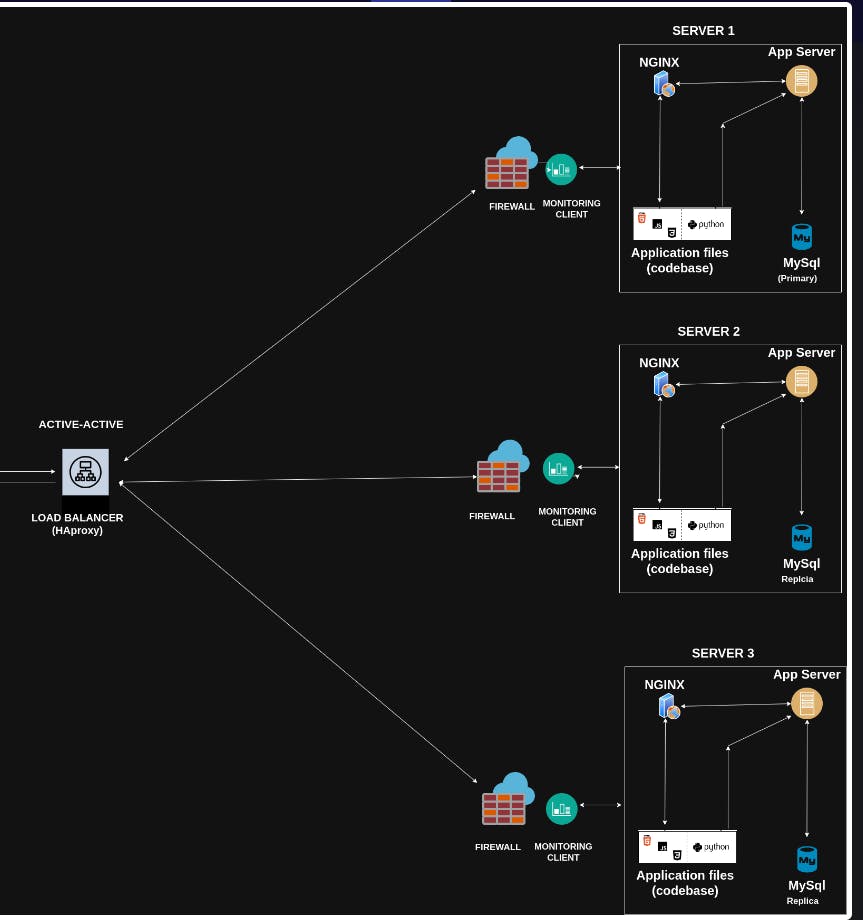
There is also the concept of firewalls, which can be software or hardware that basically monitor the traffic coming in and out of a network. There are basically two types of firewalls: host-based and network-based. Host-based ones are those that are on the computer itself, while network-based ones are those placed in between two networks, most commonly between the internet and the local network.
Web server and Application server: A web server basically serves website documents to any devices that request them. Web servers like Nginx, Apache are basically installed on a server (Linux most times) and then configured to serve a website. Whenever a client requests the website files, the Nginx, which is listening on port 80 or 443, will then serve the website to the client. Port 80 is for HTTP and 443 for HTTPS. An application server, on the other hand, is used for serving dynamic content which requires application logic. Both application server and web server work hand in hand and are sometimes deployed on the same server. A simple difference is that the web server serves the client static files while the application server works together with the web server to serve the client dynamic content.
Database:
Databases are ways of storing our information for easy access, update, creation, and deletion. We have mainly two types of databases, SQL (Structured Query Language) and NoSQL database. SQL, otherwise known as relational databases, use SQL language for interacting with the database file. NoSQL does not use SQL. We have different examples of databases, such as MySQL, SQLite, Oracle database, Postgresql, which are basically SQL-based databases. We also have NoSQL databases like MongoDB, Cassandra, etc. For the continuation of our discussion about typing www.google.com, the web server will serve the client the required document, and if it needs to check the database, it will do that.
Redundancy and preventing single points of failure:
The truth is that right now, I am tired of writing, but this is a very important concept. If you are in charge of the servers or network, you want to ensure that if one part of the system fails, it will not affect the whole operation or it will be easy to restore. Another reason is that when your customer base starts growing, you need to have multiple web servers, databases, app servers to ensure fast operations. This is what we know as redundancy and preventing single points of failure. There are multiple ways of doing that, and I will be talking about some of them.
Load balancer
Load balancer basically is in charge or distributing network traffic to different servers based on the how it is configure. Big company like Amazon do not have one web server, they probaly have thousands. Load balancers is then use to configure the network so that it can be distributed accross the webserver. So, when a user request for a website, the DNS will give it a IP address based on the configurations of the Load balancers. Load balance are configured to ensure that you get the IP address of the nearest available server near you or sometimes based on some algorithm like:-
Round robbin :- It basically share the traffic among the server equally on after the other. So, if the first traffic comes, it give it to the first server, the second to the second, if the number of server is two it will give the third to the first.
Least connected:- It basically give it less busy server
Least Response time:- It basically give it to the server that first respond to the request. There lot of other algorithm but, I will stops here.
There are different examples of load balancers; we have HaProxy, which I am currently using. Nginx web server can also serve as load balancers.
Load balancers are also classified into two types: application layer and transport layer load balancers. The basic difference between the two is that if a client is able to connect with the server using the transport layer IP, the client will keep connecting to the same server all the time, whereas for the application layer, it will keep changing for each connection.
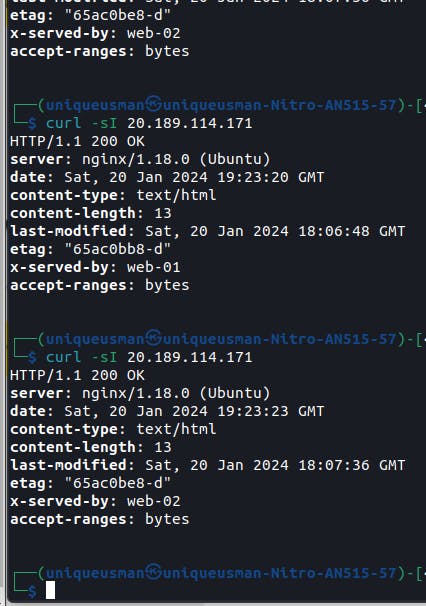
The above picture shows different web servers serving the same content whenever I send a request to the servers using curl. I used the round-robin algorithm and HAProxy load balancers, which I installed on one server. I basically have two different servers running Nginx. If you look at the picture and find "x-served-by," you will see in the first picture it is "web-01" and in the second, it is "web-02."
Database Replication
SQL replication, available in databases like MySQL, MariaDB, and PostgreSQL, offers failover solutions and performance enhancements. Primary-replica replication involves a primary "master" server handling writes and updates, continuously copying data to a replica "slave" server. This setup distributes reads for improved performance and facilitates failover. Primary-Primary replication allows both servers to accept writes, with changes transferred bidirectionally. While more complex using replication method, it ensures that when there is a problem like a flood in the database, the data can easily be recovered through the other database. Another reason might be just to have a failover if one of the databases fails. It also increases the speed of operation with the database as the operations are distributed among the databases.
Backup:
This is basically just backing up the database for recovery purposes in case the data center is flooded or something bad happens. Then you can easily recover your database.
Below are basically two images that actually encompass everything that we have been talking about. Note: The two images are together. I had to split them into two for resolution's sake.
Conclusion
If you are able to complete this, then, you would have learnt a lot about networking.